Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
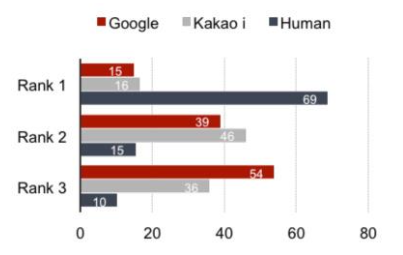
This paper proposes the first evaluation of NMT in the Spanish-Korean language pair. Four types of human evaluation —Direct Assessment, Ranking Comparison and MT Post-Editing(MTPE) time/effort— and one semi-automatic methods are applied. The NMT engine is represented by Google Translate in newswire domain. After assessed by six professional translators, the engine demonstrates 78% of performance and 37% productivity gain in MTPE. Additionally, 40.249% of the outputs of the engine are modified with an interval of 15 months, showing 11% of progress rate.

SacreBLEU, by incorporating a text normalizing step in the pipeline, has become a rising automatic evaluation metric in recent MT studies. With agglutinative languages such as Korean, however, the lexical-level metric cannot provide a conceivable result without a customized pre-tokenization. This paper endeavors to examine the influence of diversified tokenization schemes –word, morpheme, subword, character, and consonants & vowels (CV)– on the metric after its protective layer is peeled off. By performing meta-evaluation with manually-constructed into-Korean resources, our empirical study demonstrates that the human correlation of the surface-based metric and other homogeneous ones (as an extension) vacillates greatly by the token type. Moreover, the human correlation of the metric often deteriorates due to some tokenization, with CV one of its culprits. Guiding through the proper usage of tokenizers for the given metric, we discover i) the feasibility of the character tokens and ii) the deficit of CV in the Korean MT evaluation.
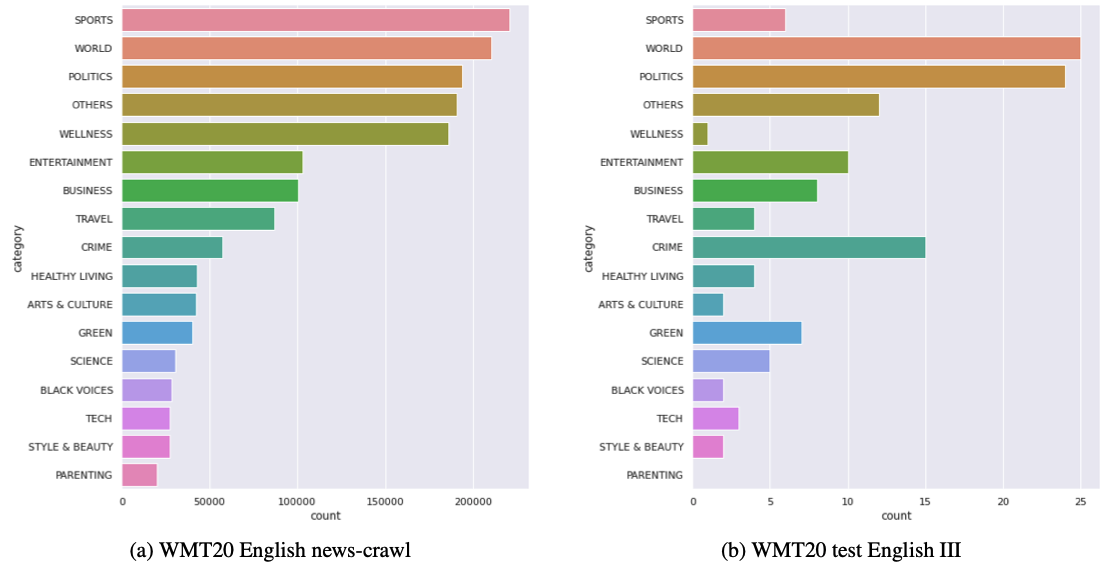
With the advent of Neural Machine Translation, the more the achievement of human-machine parity is claimed at WMT, the more we come to ask ourselves if their evaluation environment can be trusted. In this paper, we argue that the low quality of the source test set of the news track at WMT may lead to an overrated human parity claim. First of all, we report nine types of so-called technical contaminants in the data set, originated from an absence of meticulous inspection after web-crawling. Our empirical findings show that when they are corrected, about 5% of the segments that have previously achieved a human parity claim turn out to be statistically invalid. Such a tendency gets evident when the contaminated sentences are solely concerned. To the best of our knowledge, it is the first attempt to question the “source” side of the test set as a potential cause of the overclaim of human parity. We cast evidence for such phenomenon that according to sentence-level TER scores, those trivial errors change a good part of system translations. We conclude that to overlook it would be a mistake, especially when it comes to an NMT evaluation.
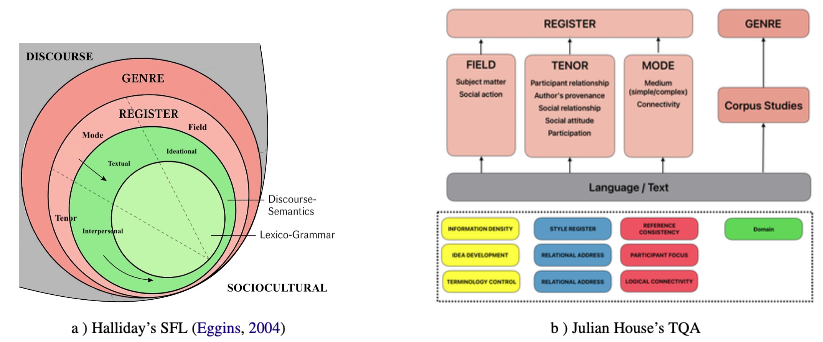
As per Michael Halliday, language is not just a system of rules, but a tool for meaningmaking within sociocultural contexts, whereby language choices shape the functions of a text. We employ Julian House's Translation Quality Assessment model inspired by Halliday's Systemic Functional Linguistics to assess Machine Translation (MT) at the document level, establishing a novel approach titled FALCON (Functional Assessment of Language and COntextuality in Narratives). It is a skillspecific evaluation framework offering a holistic view of document-level translation phenomena with fine-grained context knowledge annotation. Rather than concentrating on the textual quality, our approach explores the discourse quality of translation by defining a set of core criteria on a sentence basis. To the best of our knowledge, this study represents the inaugural attempt to extend MT evaluation into pragmatics. We revisit WMT 2024 with the English-to-X test set encompassing German, Spanish, and Icelandic, assessing 29 distinct systems in four domains. We present groundbreaking but compelling findings concerning document-level phenomena, which yield conclusions that differ from those established in existing research. Emphasizing the pivotal role of discourse analysis in current MT evaluation, our findings demonstrate a robust correlation with human values, inclusive of the ESA gold scores.
Referred to as LLM-as-judge, a generative large language model (LLM) has demonstrated considerable efficacy as an evaluator in various tasks, including Machine Translation (LAJ-MT) by predicting scores or identifying error types for individual sentences. However, its dependability in practical application has yet to be demonstrated, as there is only an approximated match due to the task’s open-ended nature. To address this problem, we introduce a straightforward and novel meta-evaluation strategy PromptCUE and evaluate cutting-edge LAJ-MT models such as GEMBA-MQM. We identify their fundamental deficits, including certain label biases and the inability to assess near-perfect translations.To improve reliability, we investigate more trustworthy and less biased models using multidimensional prompt engineering. Our findings indicate that the combination of span-level error quantification and a rubric-style prompt tailored to the characteristics of LLMs has efficiently addressed the majority of the challenges current LAJ-MT models face. Furthermore, it demonstrates a considerably enhanced alignment with human values. Accordingly, we present Rubric-MQM, the LAJ-MT for high-end models and an updated version of GEMBA-MQM.

We present IR_Multi-agentMT, our submission to the WMT25 General Shared Task. The system adopts an AI-agent paradigm implemented through a multi-agent workflow, Prompt Chaining, in combination with RUBRIC-MQM, an automatic MQM-based error annotation metric. Our primary configuration follows the Translate–Postedit–Proofread paradigm, where each stage progressively enhances translation quality. We conduct a preliminary study to investigate (i) the impact of initial translation quality and (ii) the effect of enforcing explicit responses from the Postedit Agent. Our findings highlight the importance of both factors in shaping the overall performance of multi-agent translation systems.
We present Multi-agentMT, our system for the WMT25 General Shared Task. The model adopts Prompt Chaining, a multi-agent workflow combined with RUBRIC-MQM, an automatic MQM-based error annotation metric. Our primary submission follows a Translate–Postedit–Proofread pipeline, in which error positions are explicitly marked and iteratively refined. Results suggest that a semi-autonomous agent scheme for machine translation is feasible with a smaller, earlier generation model in low-resource settings, achieving comparable quality at roughly half the cost of larger systems.
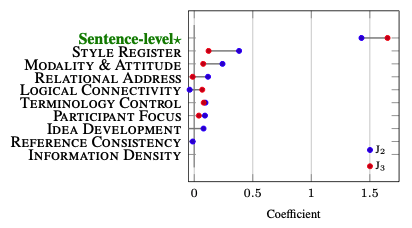
As sentence-level performance in modern Machine Translation (MT) has plateaued,reliable document-level evaluation is increasingly needed.While the recent FALCON framework with pragmatic features offers a promising direction, its reliability and reproducibility are unclear.We address this gap through human evaluation,analyzing sources of low inter-annotator agreement and identifying key factors. Based on these findings,we introduce H-FALCON,a Human-centered refinement of FALCON. Our experiments show that, even with limited annotator consensus,H-FALCON achieves correlations comparable to or better than standard sentence-level protocols. Furthermore, we find that contextual information is inherent in all sentences, challenging the view that only some require it. This suggests that prior estimates such as “n% of sentences require context” may stem from methodological artifacts. At the same time,we show that while context is pervasive,not all of it directly influences human judgment.
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.

Automatic post-editing (APE) aims to refine machine translations by correcting residual errors. Although recent large language models (LLMs) demonstrate strong translation capabilities, their effectiveness for APE--especially under document-level context--remains insufficiently understood. We present a systematic comparison of proprietary and open-weight LLMs under a naive document-level prompting setup, analyzing APE quality, contextual behavior, robustness, and efficiency. Our results show that proprietary LLMs achieve near human-level APE quality even with simple one-shot prompting, regardless of whether document context is provided. While these models exhibit higher robustness to data poisoning attacks than open-weight counterparts, this robustness also reveals a limitation: they largely fail to exploit document-level context for contextual error correction. Furthermore, standard automatic metrics do not reliably reflect these qualitative improvements, highlighting the continued necessity of human evaluation. Despite their strong performance, the substantial cost and latency overheads of proprietary LLMs render them impractical for real-world APE deployment. Overall, our findings elucidate both the promise and current limitations of LLM-based document-aware APE, and point toward the need for more efficient long-context modeling approaches for translation refinement.
Subword tokenization critically affects Natural Language Processing (NLP) performance, yet its behavior in morphologically rich and low-resource language families remains under-explored. This study systematically compares three subword paradigms -- Byte Pair Encoding (BPE), Overlap BPE (OBPE), and Unigram Language Model -- across six Uralic languages with varying resource availability and typological diversity. Using part-of-speech (POS) tagging as a controlled downstream task, we show that OBPE consistently achieves stronger morphological alignment and higher tagging accuracy than conventional methods, particularly within the Latin-script group. These gains arise from reduced fragmentation in open-class categories and a better balance across the frequency spectrum. Transfer efficacy further depends on the downstream tagging architecture, interacting with both training volume and genealogical proximity. Taken together, these findings highlight that morphology-sensitive tokenization is not merely a preprocessing choice but a decisive factor in enabling effective cross-lingual transfer for agglutinative, low-resource languages.
This is a description of a teaching experience. You can use markdown like any other post.
This is a description of a teaching experience. You can use markdown like any other post.